01. Semantic Segmentation vs Instance Segmentation
1. Segmentation 에 대한 이해

- Segmentation : 이미지를 픽셀 단위로 나누어 특정 픽셀이 무엇인지를 파악하는 task
- Semantic Segmentation : 하나의 이미지 안에 들어있는 객체의 종류 (object category)를 픽셀 단위로 찾자.
- Instance Segmentation : 하나의 이미지 안에 들어있는 객체의 개체 (object instance)를 픽셀 단위로 찾자
- Instance Segmentation = Semantic Segmentation + 'distinguishing instances"
- 픽셀단위로 task를 진행하기 때문에 비용이 많이 든다.
02. U-Net 구조를 통해서 Segmentation 이해하기
1. Semantic segmentation의 목표

- label을 픽셀 단위로 맞추는것이다.
- 이미지가 주어졌을 때, 이미지와 동일한 높이와 너비를 가진 Segmentation map을 생성하기
- classification과 regression모두 가능
2. U-Net 모델 대략적으로 살펴보기

- Encoder : 압축
- convolution을 연속적을 수행
- Decoder : 압축 해제
- transposed convolution을 수행
- U-net의 위의 과정에서 Skip Connection만 추가하면 된다.
- Skip Connection :
- ResNet에서 사용됨
- Gradient의 highway
3. U-net모델 속 연산 확인하기
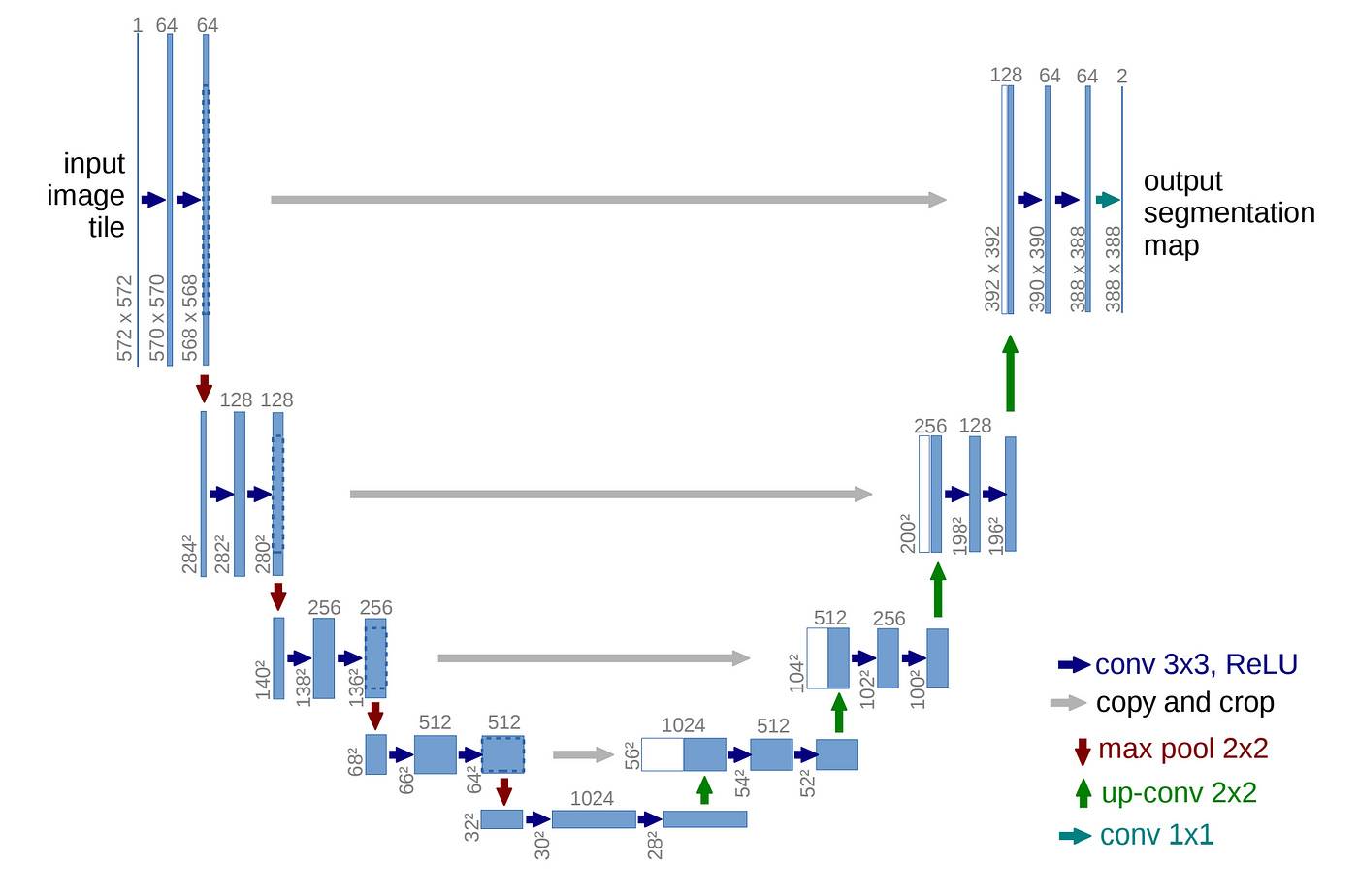
- Encoder 부분
- 전형적인 CNN구조
- 아래의 과정 반복
- 3 x 3 convolution 2번
- Padding 사용하지 않음
- ReLU activation
- 2x2 max pooling
- Down sampling후 convolution channel size가 2배
- Decoder 부분
- 아래의 과정 반복
- 2x2 up-convolution
- up-convolution (up-sampling)후 channel의 수가 1/2이 됨
- feature map의 size는 늘어남
- feature map을 cropped한것과 up-sampling한것을 concatenation
- 마지막 layer에 1x1 convolution 연산
- 2x2 up-convolution
- 아래의 과정 반복
- U-Net은 input size가 output size보다 더 크다
4. Contraction Path( Encoder)

- CNN 구조와 유사함
- 3X3 kernel을 사용하는 VGG 모델과 매우 유사함
- 입력 이미지가 가지고 있는 context정보를 추출
- 압축이 게속 되면 이미지의 위치에 대한 정보가 차츰 사라짐
- so, Encoder의 결과값을 다시 원래 size로 복구해야함
5. Expanding(Expansive) Path (Decoder)

- Low resolution의 latent representation을 high resolution으로 변형함
- Contracting path에서 만들어진 feature map을 cropping한 결과물(Skip Connection)이 concatenation됨.
- 원본 이미지가 가지고 있었던 위치 정보가 복원됨.
6. Skip Connection
- Decoding단게에서, 저차원의 정보와 고차원의 정보도 함께 이용한다.
- 인코딩 과정에서의 정보 손실을 보충
실습
# 모듈 설치
!pip install graphviz
!pip install pydot- 모듈 불러오기
import tensorflow.keras.layers as layers
import tensorflow as tf- model 구조 설계
inputs = layers.Input(shape=(572, 572, 1))
# Contracting path 시작
# [1]
conv0 = layers.Conv2D(64, activation='relu', kernel_size = 3)(inputs)
conv1 = layers.Conv2D(64, activation='relu', kernel_size=3)(conv0) # Skip connection으로 Expanding path로 이어질 예정
conv2 = layers.MaxPool2D(pool_size=(2, 2), strides=(2, 2))(conv1)
# [2]
conv3 = layers.Conv2D(128, activation='relu', kernel_size = 3)(conv2)
conv4 = layers.Conv2D(128, activation='relu', kernel_size = 3)(conv3)
conv5 = layers.MaxPool2D(pool_size=(2,2), strides=(2,2))(conv4)
# [3]
conv6 = layers.Conv2D(256, activation='relu',kernel_size = 3)(conv5)
conv7 = layers.Conv2D(256, activation = 'relu', kernel_size = 3)(conv6)
conv8 = layers.MaxPool2D(pool_size = (2,2), strides = (2,2))(conv7)
# [4]
conv9 = layers.Conv2D(512, activation = 'relu', kernel_size = 3)(conv8)
conv10 = layers.Conv2D(512, activation = 'relu', kernel_size = 3)(conv9)
conv11 = layers.MaxPool2D(pool_size = (2,2), strides = (2,2))(conv10)
# [5]
conv12 = layers.Conv2D(1024, activation='relu', kernel_size=3)(conv11)
conv13 = layers.Conv2D(1024, activation='relu', kernel_size=3)(conv12)
# Contracting path 끝
# Expanding path 시작
# [6]
trans01 = layers.Conv2DTranspose(512, kernel_size=2, strides=(2, 2), activation='relu')(conv13)
crop01 = layers.Cropping2D(cropping=(4, 4))(conv10)
concat01 = layers.concatenate([trans01, crop01], axis=-1)
# [7]
conv14 = layers.Conv2D(512, activation='relu', kernel_size=3)(concat01)
conv15 = layers.Conv2D(512, activation='relu', kernel_size=3)(conv14)
trans02 = layers.Conv2DTranspose(256, kernel_size=2, strides=(2, 2), activation='relu')(conv15)
# [8]
crop02 = layers.Cropping2D(cropping=(16, 16))(conv7)
concat02 = layers.concatenate([trans02, crop02], axis=-1)
# [9]
conv16 = layers.Conv2D(256, activation = 'relu', kernel_size = 3)(concat02)
conv17 = layers.Conv2D(256, activation = 'relu', kernel_size = 3)(conv16)
trans03 = layers.Conv2DTranspose(128, kernel_size = 2, strides=(2,2), activation= 'relu')(conv17)
# [10] (cropping=(40, 40))
crop03 = layers.Cropping2D(cropping = (40,40))(conv4)
concat03 = layers.concatenate([trans03, crop03], axis = 1)
# [11]
conv18 = layers.Conv2D(128, activation = 'relu', kernel_size=3)(concat03)
conv19 = layers.Conv2D(128, activation = 'relu', kernel_size = 3)(conv18)
trans04 = layers.Conv2DTranspose(64, kernel_size = 2, strides =(2,2), activation = 'relu')(conv19)
# [12](cropping=(88, 88))
crop04 = layers.Cropping2D(cropping = (88,88))(conv1)
concat04 = layers.concatenate([trans04, crop04], axis = 1)
# [13]
conv20 = layers.Conv2D(64, activation='relu', kernel_size=3)(concat04)
conv21 = layers.Conv2D(64, activation='relu', kernel_size=3)(conv20)
# Expanding path 끝
# 1x1 conv
outputs = layers.Conv2D(2, kernel_size=1)(conv21)
model = tf.keras.Model(inputs=inputs, outputs=outputs, name="u-netmodel")model.summary()Model: "u-netmodel"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_5 (InputLayer) [(None, 572, 572, 1) 0
__________________________________________________________________________________________________
conv2d_58 (Conv2D) (None, 570, 570, 64) 640 input_5[0][0]
__________________________________________________________________________________________________
conv2d_59 (Conv2D) (None, 568, 568, 64) 36928 conv2d_58[0][0]
__________________________________________________________________________________________________
max_pooling2d_16 (MaxPooling2D) (None, 284, 284, 64) 0 conv2d_59[0][0]
__________________________________________________________________________________________________
conv2d_60 (Conv2D) (None, 282, 282, 128 73856 max_pooling2d_16[0][0]
__________________________________________________________________________________________________
conv2d_61 (Conv2D) (None, 280, 280, 128 147584 conv2d_60[0][0]
__________________________________________________________________________________________________
max_pooling2d_17 (MaxPooling2D) (None, 140, 140, 128 0 conv2d_61[0][0]
__________________________________________________________________________________________________
conv2d_62 (Conv2D) (None, 138, 138, 256 295168 max_pooling2d_17[0][0]
__________________________________________________________________________________________________
conv2d_63 (Conv2D) (None, 136, 136, 256 590080 conv2d_62[0][0]
__________________________________________________________________________________________________
max_pooling2d_18 (MaxPooling2D) (None, 68, 68, 256) 0 conv2d_63[0][0]
__________________________________________________________________________________________________
conv2d_64 (Conv2D) (None, 66, 66, 512) 1180160 max_pooling2d_18[0][0]
__________________________________________________________________________________________________
conv2d_65 (Conv2D) (None, 64, 64, 512) 2359808 conv2d_64[0][0]
__________________________________________________________________________________________________
max_pooling2d_19 (MaxPooling2D) (None, 32, 32, 512) 0 conv2d_65[0][0]
__________________________________________________________________________________________________
conv2d_66 (Conv2D) (None, 30, 30, 1024) 4719616 max_pooling2d_19[0][0]
__________________________________________________________________________________________________
conv2d_67 (Conv2D) (None, 28, 28, 1024) 9438208 conv2d_66[0][0]
__________________________________________________________________________________________________
conv2d_transpose_10 (Conv2DTran (None, 56, 56, 512) 2097664 conv2d_67[0][0]
__________________________________________________________________________________________________
cropping2d_10 (Cropping2D) (None, 56, 56, 512) 0 conv2d_65[0][0]
__________________________________________________________________________________________________
concatenate_10 (Concatenate) (None, 56, 56, 1024) 0 conv2d_transpose_10[0][0]
cropping2d_10[0][0]
__________________________________________________________________________________________________
conv2d_68 (Conv2D) (None, 54, 54, 512) 4719104 concatenate_10[0][0]
__________________________________________________________________________________________________
conv2d_69 (Conv2D) (None, 52, 52, 512) 2359808 conv2d_68[0][0]
__________________________________________________________________________________________________
conv2d_transpose_11 (Conv2DTran (None, 104, 104, 256 524544 conv2d_69[0][0]
__________________________________________________________________________________________________
cropping2d_11 (Cropping2D) (None, 104, 104, 256 0 conv2d_63[0][0]
__________________________________________________________________________________________________
concatenate_11 (Concatenate) (None, 104, 104, 512 0 conv2d_transpose_11[0][0]
cropping2d_11[0][0]
__________________________________________________________________________________________________
conv2d_70 (Conv2D) (None, 102, 102, 256 1179904 concatenate_11[0][0]
__________________________________________________________________________________________________
conv2d_71 (Conv2D) (None, 100, 100, 256 590080 conv2d_70[0][0]
__________________________________________________________________________________________________
conv2d_transpose_12 (Conv2DTran (None, 200, 200, 128 131200 conv2d_71[0][0]
__________________________________________________________________________________________________
cropping2d_12 (Cropping2D) (None, 200, 200, 128 0 conv2d_61[0][0]
__________________________________________________________________________________________________
concatenate_12 (Concatenate) (None, 400, 200, 128 0 conv2d_transpose_12[0][0]
cropping2d_12[0][0]
__________________________________________________________________________________________________
conv2d_72 (Conv2D) (None, 398, 198, 128 147584 concatenate_12[0][0]
__________________________________________________________________________________________________
conv2d_73 (Conv2D) (None, 396, 196, 128 147584 conv2d_72[0][0]
__________________________________________________________________________________________________
conv2d_transpose_13 (Conv2DTran (None, 792, 392, 64) 32832 conv2d_73[0][0]
__________________________________________________________________________________________________
cropping2d_13 (Cropping2D) (None, 392, 392, 64) 0 conv2d_59[0][0]
__________________________________________________________________________________________________
concatenate_13 (Concatenate) (None, 1184, 392, 64 0 conv2d_transpose_13[0][0]
cropping2d_13[0][0]
__________________________________________________________________________________________________
conv2d_74 (Conv2D) (None, 1182, 390, 64 36928 concatenate_13[0][0]
__________________________________________________________________________________________________
conv2d_75 (Conv2D) (None, 1180, 388, 64 36928 conv2d_74[0][0]
__________________________________________________________________________________________________
conv2d_76 (Conv2D) (None, 1180, 388, 2) 130 conv2d_75[0][0]
==================================================================================================
Total params: 30,846,338
Trainable params: 30,846,338
Non-trainable params: 0- 그림으로 나타내기
from IPython.display import SVG
from keras.utils.vis_utils import model_to_dot
%matplotlib inline
SVG(model_to_dot(model, show_shapes= True, show_layer_names=True, dpi=80).create(prog='dot', format='svg')) #dpi를 작게 하면 그래프가 커집니다.
03. Transposed Convolution 코드
- Transposed Convolution
- CNN과 반대로 입력 데이터의 크기를 키우는 작업을 수행한다.
- 입력 feature map의 공간 해상도를 높이기 위한 작업
# 필요한 모듈 불러오기
import numpy as np
import tensorflow as tf
# input data
X = np.asarray([[1, 2],
[3, 4]])
print(X)
print(X.shape)[[1 2]
[3 4]]
(2, 2)# 모델에 맞게 reshaping
X = X.reshape((1, 2, 2, 1))
print(X)
print(X.shape)[[[[1]
[2]]
[[3]
[4]]]]
(1, 2, 2, 1)
# 모델 만들기
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Conv2DTranspose(1, (1, 1), strides=(2, 2), input_shape=(2, 2, 1))) # Conv2DTranspos layer- weights를 설정하고 설정한 weights를 모델에 적용
weights = [np.asarray([[[[1]]]]), np.asarray([1])] # weight = 1, bias = 1
weights[array([[[[1]]]]), array([1])]model.set_weights(weights)- 결과 확인
yhat = model.predict(X)
yhat = yhat.reshape((4, 4)) # 결과를 확인하기 편하게 reshaping
print(yhat)[[2. 1. 3. 1.]
[1. 1. 1. 1.]
[4. 1. 5. 1.]
[1. 1. 1. 1.]]
'하루 30분 컴퓨터 비전 공부하기' 카테고리의 다른 글
| CV(11) 실습편 Object Detection (0) | 2023.11.01 |
|---|---|
| CV(10) Image Classification/코드 실전편 (0) | 2023.10.31 |
| CV(7) Object Detection과 R-CNN (0) | 2023.10.27 |
| CV(6) CNN 정복하기 - Transfer Learning 기본 (1) | 2023.10.27 |
| CV(5) CNN 정복하기 GoogLeNet - 심화된 CNN 구조 (1) | 2023.10.26 |



