01. Image Classification vs. Localization vs.Object Detection
1. Computer Vision 내의 task

- Classification
- 하나의 대상의 true label 이 무엇인지 분류하기
- Localization
- 하나의 대상의 위치를 가장 적절하게 지정하는 Bounding Box찾기
- Object Detection
- Bounding Box로 객체의 위치를 표시하고 각 객체를 classification을 하는 것이다.
- Segmentation
- Semantic Segmentation : 픽셀단위로 classification 하는 것
2. Localization ( + Classification ) vs. Object Detection
- Localization과 Detection 모두 대상의 위치를 Bounding Box로 지정
- object Detection을 사용하면 feature는 잘 찾아내지만 object Detection으로 사용하기엔 무리가 있다.
02. Object Detection 모델의 발전 과정

1. object Detection 모델 발전 과정
- AlexNet
- One-stage Detecor
- regin proposal과 classification / bounding box를 구분하지 않고 한번에 진행
- ex) YOLO
- Two-stage Detector
- Detection을 하는데 2가지 stage를 진행함
- stage 1 : regin proposal
- stage 2 : classification / bounding box
- ex) Faster RCNN
- Detection을 하는데 2가지 stage를 진행함
2. Two-stage Detector
- ex) Faster R-CNN
- stage 1
- Proposal : Region Proposal 을 하는 부분
- stage 2
- Classifier : 분류하는 부분
- Region Proposal을 먼저 진행하면서 이미지 내에 대상이 있을 법한 영역인 RoI(Region of Interest)를 찾아낸다.
- 찾아낸 RoI안에 있는 이미지를 classification 한다.
- 두 단계로 나누어져서 느리지만, 정확도가 비교적 높다는 장점이 존재한다.
3. One-stage Detector
- ex) YOLO
- Regin Proposal과 Classification을 동시에 수행한다.
- Rol를 찾아내는 대신, 이미지 저체를 대상으로 Classification을 수행한다.
- YOLO v1의 경우에는 전체 이미지를 특정 크기의 그리드로 분할한 후, 특정 cell에 대하여 classification을 수행한다.
- 정확도가 조금 떨어질수 있겠다.
- 영상과 같이 실시간을 Object Detection을 할 때 One-stage Detector를 사용한다.
03. R-CNN 모델을 통해 Object Detection 이해하기
1. R-CNN의 전체 구조
- Two-stage Detector 이다.
- Region Proposal을 진행후 warped(모양 변경)을 진행
- 이후 CNN에서 Feature Extractor와 관련 부분만 가져와서 연결
- 추출된 Feature를 가지고 clssification을 진행한다.
- 1. Region proposal : 입력 이미지에 selective search 알고리즘을 적용하여 객체가 있을 만한 RoI의 후보 2천개를 추출.
- 최근에는 selective search 대신 딥러닝을 사용한 알고리즘을 사용하고 있음
- 2. resize : 추출된 RoI의 후보 2천개를, 227 * 227로 변형(동일한 size로 변경)
- resize하면서 이미지에 왜곡이 생김
- 3. 이미 학습된 CNN구조를 통해서 4096차원의 특징 벡터 추출
- 4. 추출된 벡터를 기반으로 하여 각각의 객체별로 학습시켜 놓은 SVM calssifier를 이용하여 분류
- 5. Bounding box regression으로 적절한 객체의 경계(bounding box) 설정
2. Region proposal: selective search

- 색, 무늬 크기, 형태를 바탕으로 주변 픽셀간의 유사도를 계산
- 유사도를 바탕으로 Segmentation을 수행한 후, 작은 segment들을 묶어가며 최종 후보를 찾는다.
- 초기 Segmentation은 매우 세밀한 영역까지 Over-Segmentation
- 유사도가 비슷한 Segment들을 반복적으로 묶어간다.
- End-to- End
- 입력이 들어가면 파이프라인을 따라 끝까지 진행
- but, R-CNN은 multi-stage pipeline으로 End-to- End가 아니다
- CNN, SVM(classification), bounding box regression(localization)으로 진행되기 때문에 연산이 공유되지 않았다.

3. Classification

- RoI를 동일한 사이즈로 맞춘 후, pre-trained model인 Convolutional Neural Network 구조를 통해서 feature Extraction(4096차원)을 수행한다.
- feature Extracion 결과 바탕으로 학습한 SVM을 통하여서 Classification을 수행한다.
- 2000개의 proposed region 중에서 IoU값을 이용해 non-maximum suppression을 적용한다.
- IoU 값을 이용해 "non-maximum suppression"을 적용해 적합하지 않은 것을 탈락
- Bounding box의 위치를 맞추기 위해서 bounding box regression을 실행한다.
04. Object Detection과 관련된 개념들
1. Sliding window

- Object Detection은 이미지의 “어느 위치”에 Object가 있는지 알아보는 태스크이다.
- Sliding window : 일정 크기의 window를 이미지 위에서 조금씩 옮겨가며 전수조사를 하는 것
- Window 사이즈를 바꿔 가면서 Object가 있는 위치를 찾고, 효율적으로 Object 위치를 찾기 위해서 stride를 변경할 수 있다.
- 그러나 계산 비용이 많이 들고 학습 속도가 느리다.
2. IoU (Intersection over Union)

- IoU는 모델이 예측한 bounding box와 실제 정답인 ground truth box가 얼마나 겹치는 지를 측정하는 지표이다.
- 만약 100%로 겹치게 되면 IoU 값은 1이다.
- Area of Union: predicted bounding box와 ground-truth bounding box를 모두 포함하는 영역
- Area of Overlap: predicted bounding box와 ground-truth bounding box가 겹치는 부분
3. NMS (Non Maximum/maximal Suppression)

- NMS은 수많은 bounding box 중 가장 적합한 box를 선택하는 기법이다.
- NMS의 과정
- 모든 bounding box에 대하여 threshold 이하의 confidence score를 가지는 bounding box는 제거한다.
- 남은 bounding box들을 confidence score 기준으로 내림차순 정렬한다.
- 정렬 후 가장 confidence score가 높은 bounding box를 기준으로 다른 bounding box와 IoU를 구한다.
- IoU가 특정 기준 값보다 높으면, confidence score가 낮은 bounding box를 제거한다.
- 해당 과정을 순차적으로 반복한다.
4. mAP (mean Average Precision)
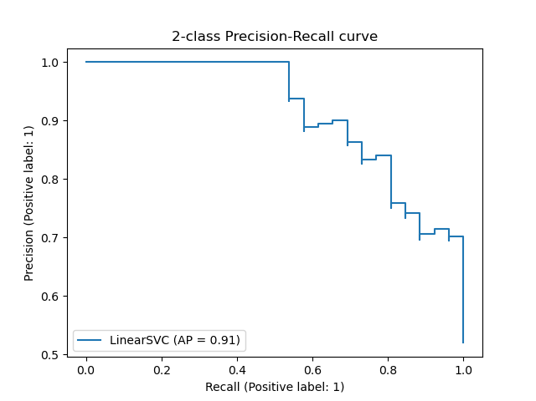
- Precision-Recall Curve: confidence threshold의 변화에 따른 정밀도와 재현율의 변화 곡선이다.
- AP: Precision-Recall Curve의 아래 부분 면적을 의미한다
- mAP: AP는 하나의 object에 대한 성능 수치이며, mAP는 여러 object들의 AP를 평균한 값을 의미한다 따라서 Object Detection 모델의 성능 평가에 사용한다
5. Bounding Box Regression
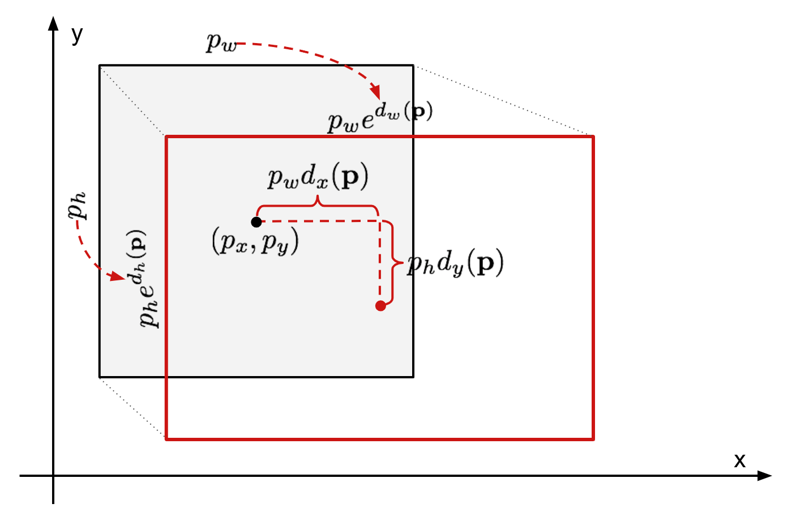
- Bounding box regression의 목표는 예측 박스()를 Ground truth box()에 가깝게 만드는 것이다
'하루 30분 컴퓨터 비전 공부하기' 카테고리의 다른 글
| CV(10) Image Classification/코드 실전편 (0) | 2023.10.31 |
|---|---|
| CV(8) Segmentation과 U-Net (0) | 2023.10.31 |
| CV(6) CNN 정복하기 - Transfer Learning 기본 (1) | 2023.10.27 |
| CV(5) CNN 정복하기 GoogLeNet - 심화된 CNN 구조 (1) | 2023.10.26 |
| CV(2) CNN 기초 - Convolution, filter, padding (0) | 2023.10.25 |



