라이브러리 설치하기
pip install pmdarima➞ R에서 실행되는 auto.arima를 파이썬에서 실행시킬수 있도록 설계된 통계 라이브러리
➞ 시계열 데이터를 분석할때 좋음
라이브러리 불러오기
import os
import requests
from io immport BytesIO
from itertools import product
from datetime import datetime
# 데이터 처리
import pandas as pd
import numpy as np
# 시각화
import matplotlib as mpl
import matplotlib.pyplot as plt
import matplotlib.ticker as plticker
import seaborn as sns
# 분석
import sklearn
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import Ridge, RidgeCV, Lasso, LassoCV
import statsmodels.api as sm
import pmdarima as pm
# statsmodels
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
from statsmodels.tsa.seasonal import STL
from statsmodels.tsa.stattools import adfuller # 정상성 검정
from statsmodels.tsa.arima_model import ARIMA
import warnings
warnings.filterwarnings('ignore')데이터 준비
file_path = os.getenv('주소')
df_raws = pd.read_csv(file_path)
df_data = df_raws.set_index('t_date').sort_index()
시계열 분석
- 시계열 데이터 : 시간 순서대로 발생한 데이터
➞ 시간과 연관되어있음
➞ 일반적인 통계분석과 차이가 있기 때문에 시계열 기법을 사용
➞ 약정상성(weak stationarity)가정을 만족해야함
- 약정상성
약정상성 가정 3가지
1. 시간(t)이 흘러도 평균이 같음.
2. 시간(t)이 흘러도 분산이 같음.
3. 자기공분산 또는 각 값들의 상관성(Auto-Correlation, 자기상관관계)이 시간이 아닌 시차에 의존.
➞ ex) (t, t+s의 공분산) == (t, t-s의 공분산)
* 시간 : 일정한 간격으로 진행되는 물리적 또는 추상적인 개념. 즉, 시간의 경과를 나타내는 개념
* 시차 : 두 지점 또는 사건 간의 시간적 차이를 의미
* 정상성 : 평균, 분산이 시간에 따라 일정한 성질
* 자기상관: 시간 또는 공간젓으로 연속된 일련의 관측치들간에 존재하는 상관관계
(https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=nlboman&logNo=23353211)
* 시간에 따란 분산과 평균이 바뀐다면 예측이 매우 어려움.
so, 시간이 흘러도 분산과 평균은 일정해야함
- 공분산
: 두개의 확률변수의 선형관계를 나타내는 값
➞ 분포가 서로 얼마나 관련있는지를 수치적으로 표현
➞ 분산 : 각 변수의 평균에서 편차를 제곱한것의 평균

X, Y: 확률번수 xi, yi: 관측값, E(X), E(Y): 평균
- 상관관계
: 공분산을 분산으로 다시 나누어 공분산을 (-1 ,1)범위로 스케일링 해준것
➞ -1에 가까울수록 음의 상관관계, 1에 가까울수록 양의 상관관계, 0에 가까울수록 상관관계가 없음
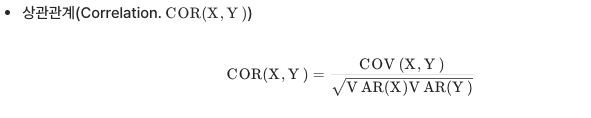
ARIMA 모형
(Auto-Regressive Integrated Moving Average)
: AR(자기회귀, Autoregression)모형과 MA(이동 평균, Moving, Average)모형을 합친 것.
: 현재값을 과거값과 과거의 예측 오차를 통해 설명.
: 비정상 시계열을 차분과 변환을 통해 AR, MA, ARMA로 정상화 시킬수 있음.
(https://be-favorite.tistory.com/63)
* AR(Auto Correlation)모형
: 시계열의 현재값을 p개의 과거값들의 선형결합으로 예측을 설명.
: 현 시점의 데이터(yt)가 p시점 전의 유한개의 과거 데이터로 설명가능.

* MA(Moving Average)모형
: 시계열을 현시점의 오차와 q개의 과거 오차들의 선형결합으로 예측을 수행
: 과거의 예측 오차를 이용하여 미래값을 예측하는 모형
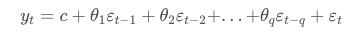
- ARIMA모형 결정 과정
1. 그래프와 검정을 통해 데이터에 계절성과 정상성이 있는지 확인
2. 데이터가 정상성을 띠지 않을 때 차분과 로그 변환을 정상성을 띠는 데이터로
➞ 평균이 일정하지 않을 때 차분, 분산이 일정하지 않을 때 로그 변환

* (a)는 변동폭이 일정하지 않고 비정상 시계열이 존재한다. (a)를 로그변환 해주면 (b)와 같이 변동폭(분산)이 일정해지고, 차분을 하면 (c)와 같이 평균이 일정해진다. 로그변환과 차분을 같이 하면 (d)와 같이 평균과 분산이 일정한 시게열이 된다.
* 로그변환 : 변동폭이 일정하지 않은 경우 큰값을 줄이고 비정규성을 줄이기위해 사용합니다. 분산변화를 일정하게 만들수 있습니다.
* 차분(differencing) : 시계열수준에서 나타나는 변화를 제거하여 추세나 계절성을 제거하는 것으로, 연속되는 관측값들의 차이를 계산하는 것입니다. / xi - x(i-1)
➞ ARIMA 유튜브 설명 갑 (https://www.youtube.com/watch?v=ma_L2YRWMHI)
3. ARIMA모형 판별하고 적합.
4. 모형이 적절한지 점검
STL 분해 (Seasonal and Trend decomposition using LOESS)
- 시계열에 내재된 Seasonal 성분과 Trend 성분을 쉽게 확인할 수 있는 방법론.
- 시계열은 trend(추세), seasonality(계절성), cycle(주기) 3가지 패턴이 존재
- STL분해의 장점
1. 어떤 종류의 계절성도 다룰 수 있음
2. seasonal window와 trend-cycle window의 매개변수를 조절해 계절성분과 추세 주기 성분을 사용자가 조정할 수있음.
3. 이상치가 추세-주기와 계절 성분에 영향을 주지 않게 만들 수 있음
-STL분해의 단점
1. 덧셈 분해만 지원
➞ 곱셈 분해를 해야하면 로그를 취해 분해를 하고 성분을 원래대로 돌려야함
- STL분해 코드로 구현하기
time_series = data['count']
STL_decomposed = STL(time_series, seasonal = 7, period = 7).fit()
fig. = STL_decomposed.plot()
fig.set_size_inches(10,16)
for ax in fig.axes :
loc = plticker.MultipleLocator(base=3.0) # 눈금의 간격을 설정
ax.xaxis.set_major_locator(loc) # 위에서 설정한 눈금을 그래프에 그림
ax.xaxis.set_major_locator(loc)
ax.tick_params(axis = 'x', labelrotation = 45)
plt.show()
- ACF(Autocorrelation Function)
: yt와 y(t+k)사이에 correlation을 측정하는것.
: yt와 y(t+k)가 얼마나 관계가 있는지.
: 먼 과거와 미래 사이의 관련성을 보여줌.
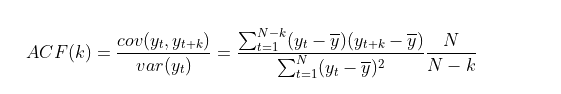
- PACF(Partial Autocorrelation Function )
: yt와 y(t+k)사이에 correlation을 측정하는것은 동일하지만 t와 t+k 사이에 다른 y값을의 영향력을 배제하고 측정.
: 특정 시차에서의 영향을 다루는데 사용.

'TIL(Today I Learned)' 카테고리의 다른 글
| likelihood와 머신러닝 (0) | 2023.09.12 |
|---|---|
| scikit-learn을 이용해 분류문제 해결하기 (0) | 2023.09.05 |
| 데이터 분석 (0) | 2023.08.30 |
| 머신러닝 모델설계하기 기초 | 내가 받을 팁 예측하기 (2) (0) | 2023.08.28 |
| 머신러닝 모델설계하기 기초(1) (0) | 2023.08.28 |


