모듈 import
from IPython.display import display, Image
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
%config InlineBackend.figure_format = 'retina' # 더 높은 해상도로 출력
데이터
- 맥북 데이터 셋
- 맥북을 사용한 사용연수와 중고가격을 나태내는데이터
먼저 데이터를 확인해 보겠습니다.
macbook = pd.read_scv('주소')
print(macbook.shape)
macbook.head()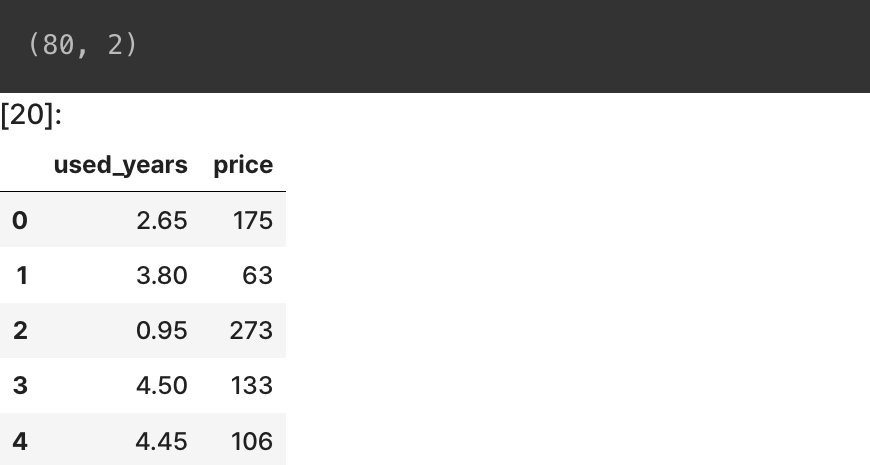
맥북데이터셋에서는 사용연수를 가지고 중고가격을 측정하였지만 사실 노트북 중고가격을 결정하는 요소들은 CPU, 배터리 수명, 외관 등 다용한 요소들이 복합적으로 작용합니다. 하지만 이번에는 사용연수만 가지고 중고가격을 유추해보도록 하겠습니다.
데이터 시각화
- 맥북데이터 셋을 이용해 한눈에 알아보기 쉽게 직관적인 그래프로 나타내 보겠습니다.
plt.scatter(macbok['used_years'], macbook['price'])
plt.show()
그래프를 보니 사용연수가 길어질 수록 중고가격이 낮아지는 것을 알 수 있습니다.
두 변수사이에 상관관계가 있을을 알 수 있습니다.
상관관계
: 한 변수의 변화에 따라 다른 변수의 변화정도와 방향을 예측하는 분석기법.
- 상관계수 : 상관관계 분석에서 두 변수 간에 선형 관계의 정도를 수량화 하는 측도.

위의 그림은 여러가지 상관관계를 나타내는 이미지이고 각각의 이미지 위에 써져있는 숫자가 상관계수 입니다.
상관계수의 값은 -1에서 1사이의 값을 가집니다. 상관관계가 없다면 0에 가까워 지고 상관관계가 있으면 절댓값이 1에 가까워 집니다.
ex)
- 상관 관계가 없음 ➞ 상관계수 : 0
- 한 변수가 커질수록 다른 변수도 커짐 ➞ 상관계수 : +
- 한 변수가 커질수록 다른 변수는 작아짐 ➞ 상관계수 : -
즉, 데이터 분포의 기울기가 양의 값이면 상관계수도 양의 값이고 데이터 분포의 기울기가 음의 값이면 상관계수도 음의 값입니다.
상관계수가 양의 값이면 두 변수는 ' 양의 상관관계'이고 음의 값이면 두 변수는 '음의 상관관계'를 가진다고 말 할 수 있습니다.
상관계수는 데이터의 분포가 직선에 가까우면 절댓값이 1에 가까워지고 원모양에 가까워 질수록 값이 0에 가까워 집니다.
이미지의 첫번째 줄 데이터를 보면 데이터의 분포가 직선에 가까워 질수록 상과계수의 절댓값이 1에 가까워지는 것을 알 수 있습니다
두번째 줄의 데이터를 보면 각각의 기울기는 다르지만 상관계수의 절대값이 모두 1인 것을 알 수 있습니다. 상관계수는 두 변수사이에 관계성 즉, 한 변수의 값이 커지면 다른 변수의 값이 어떻게 변하는지에 대한 '상호적인 관계의 정도'를 나타내기 때문에 기울기와 상관없이 데이터의 분포가 직선에 가까우면 1또는 -1에 가까워집니다.
이미지의 마지막 줄은 데이터의 분포가 어떤 모양이든 양도는 음의 상관관계를 가지고 있지 않기 때문에 상관계수가 0이라고 할 수 있습니다.
상관계수 구하기
#corrcoef() 함수 사용법
import numpy as np
np.corrcoef(x, y)import numpy as np
np.corrcoef(macbook['used_years'], macbook['price']) # 상관계수를 나타내는 함수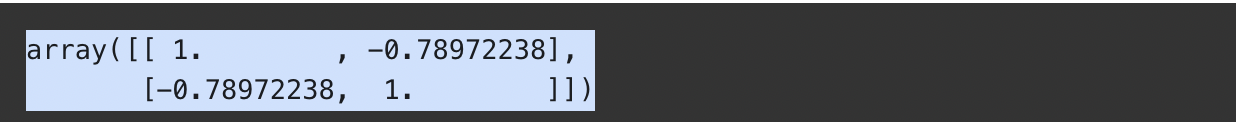
대각선에 해당하는 (0,0)과 (1,1)의 값은 항상 1입니다. 왜냐하면 자기 자신과의 상관관계를 나타내기 때문입니다.
(0,1)과 (1,0)의 값을 보면 -0.789...로 -1에 가까운 것을 알 수 있습니다. 따라서 두 변수는 강한 상관관계가 있습니다.
이제 본격적으로 사용연수를 사용하여 중고가를 예측해 보도록 하겠습니다.
먼저, x, y 에 각각 'used_years'의 값과 'price'의 값을 넣어주겠습니다.
x = macbook['used_years'].values
y = macbook['price'].values간단한 인공지능 모델 구현하기
일차함수 모델
일단 , 간단한 일차 함수 모델을 만들어 보도록 하겠습니다
def model(x, w, b):
y = w * x + b # w : 기울기, y : y 절편
return y이제 우리가 만든 일차함수를 가지고 모델을 학습 시켜 보도록 하겠습니다.
모델 학습은 모델이 데이터를 입력받았을 때 정답에 가까운 값을 낼 수 있도록 최적의 파라미터 값(매개변수 값)을 찾는것 입니다.
<간단 인공지능 용어 정리>
모델 : 프로그램
학습 : 컴퓨터가 스스로 데이터의 규칙을 찾아내는 기술
훈련 : 규칙을 찾고 정화도를 높이는 방향으로 수정하는 과정 / 학습을 구현하기 위한 과정
입력 : 모델이 규칙을 찾아야할 대상
타깃 : 모델이 맞춰야할 정답
다시말해 모델 학습은 최적의 w와 b의 값을 찾는 것 입니다.
우리의 데이터를 살펴보면
위의 그림과 같이 쉽게 직선 그래프로 나타낼수는 없을것 같습니다. 하지만 최대한 많은 점들을 통과하는 최적에 가까운 일차함수를 찾아봅시다. 현실의 모든 데이터는 위의 그림과 같이 하나의 직선이나 곡선으로 표현하기에는 무리가 있습니다. 그렇지만 최대한 가깝게, 오차가 적은 적절한 모델을 찾아내는 것이 우리의 목표입니다.
손실함수 : 실제값 - 예측값
실제값과 예측값의 차이를 점차 줄여나가는 방향으로 모델을 학습 시킬 수 있습니다.
모델을 학습시키기위해 우리가 첫번째로 할 일은 파라미터에 랜덤 값을 넣어주는 것 입니다.ㅣ
지금은 어떤값이 좋은 파라미터 값인지 알 수 없으니 랜던한 값을 넣어준 다음 손실함수를 사용하여 점차 오차를 줄여나가는 방식이죠.
w = 3.1 # 랜덤값 w
b = 2.3 # 랜덤값 b
x = np.linspace(0,5,6)
y = model(x, w, b) #y = 3.1x + 2.3
plt.scatter(macbook['used_year'], macbook['price'])
plt.show()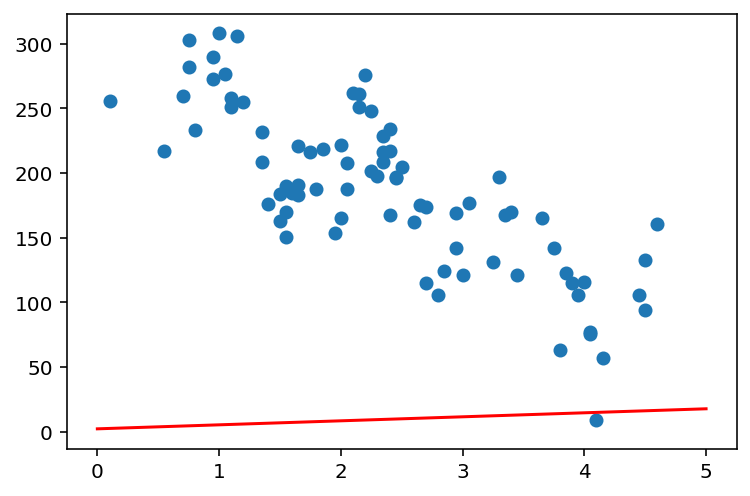
오차가 너무 크군요.
맥북데이터 셋에 있는 실제 price값과 얼마나 차이가 나는지 확인해 보도록 합시다.
x = macbook['used_years'].values # x에 사용연수를 넣어줌
predic = model(x, w, b) # 현재 예측한 price값
macbook['prediction'] = predic # 예측값 df에 추가하기
macbook.head()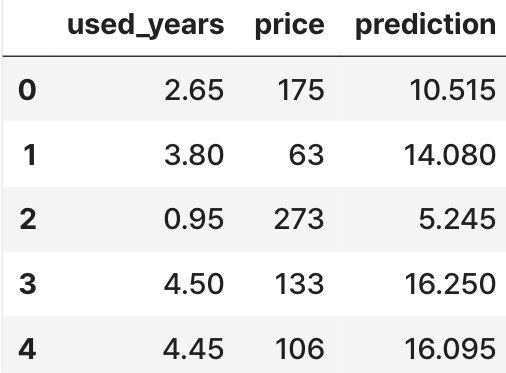
생각보다 예측값이 많이 차이 나네요. 실제값과 예측값의 오차를 계산해 봅시다.
macbook['error'] = macbook['price'] - macbook['prediction'] # 실제값 - 예측값
mackbook.head()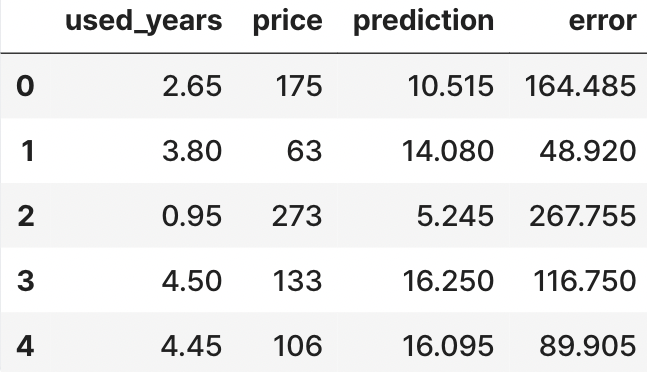
오차값이 꽤 차이가 나네요.
그럼 방금 구한 error를 가지고 모델의 손실함수를 구해 봅시다.
손실값의 종류
MAE : mean absolute error (평균 절대 오차)
MSE : mean squared error ( 평균제곱오차)
RMSE : Root Mean Squared Error (MSE의 제곱근)
R-squared : Coefficient of Determination (결정 계수)
손실함수는 현재의 모델이 얼마나 예측을 잘하고 있는지를 나타낼 수 있습니다.
우리는 RMSE를 사용해서 손실함수를 구현해 봅시다.
# RMSE
def RMSE(prediction, y):
mse = ((prediction - y) ** 2).mean() # 두 값의 차이의 제곱의 평균
rmse = mse**0.5 # MSE의 제곱근
return rmse
# rmse 값 구하기
rmse = RMSE(predic, y)
rmse188.81322969819274우리가 파라미터로 랜덤한 값을 넣었기 때문에 rmse값이 매우 크게 나타납니다.
rmse값이 크다는 것은 실제값과 예측값이 차이가 많이 난다는 것을 의미합니다.
그렇다면 rmse를 사용하여 손실함수를 구현해보겠습니다.
def loss(x, w, b, y) :
predictions = model(x, w, b)
L = RMSE(predictions, y)
return L
기울기와 경사하강법(Gradient Descent)
: 함수의 기울기를 구하여서 경사의 반대방향으로 이동시켜 극값으로 수렴시키는것 입니다.
- 경사하강법을 이용하는 이유?
➞ 손실함수는 실제값과 예측값의 차이를 나타내는 함수입니다. 그렇기 때문에 error값이 최소가 될수록 실제값과 예측값이 비슷하다고 할 수 있고 잘 예측했다고 할 수 있습니다. 그래서 기울기가 0인 곳이 최적의 파라미터라고 할 수 있습니다.
- 근사값을 찾는 과정
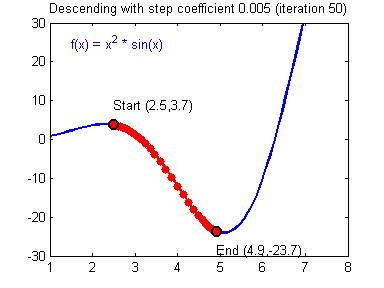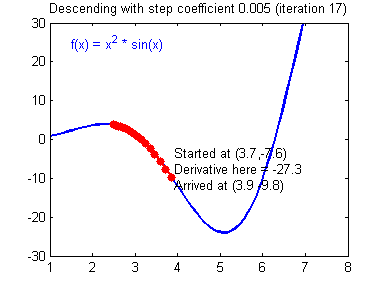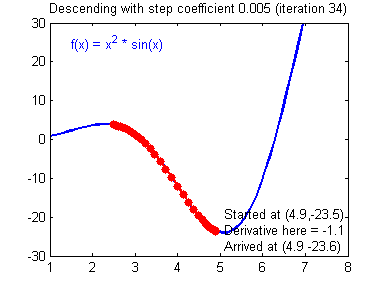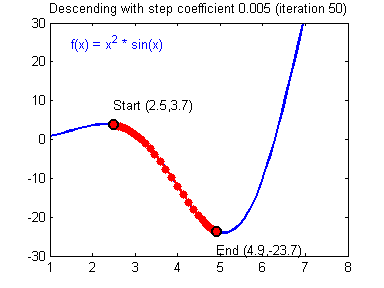
➞ 현재의 기울기 값이 음수라면 기울기의 값을 증가 , 기울기값이 양수라면 기울기의의 값을 감소시켜서 기울기가 0인 최솟값을 찾을 수있습니다.
기울기 업데이트
식) w' = w - ηg
w' : 새로운 w
w : 현재 w
η : learning rate
g : gradiant(기울기)
➞
문제점
➞ 적절한 learning rate를 찾는 것이 어렵다
➞ local minimum에 빠질 수 있다.
미분으로 경사구하기
기울기를 구하는 식은 간단합니다.
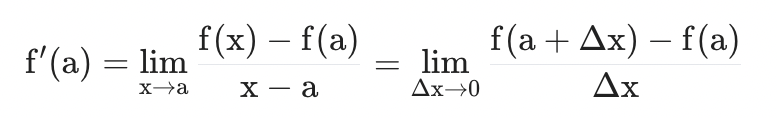
실제로 우리가 갱신해야하는 값은 w와 b 두가지입니다.
이제 코드로 식을 구현해 보겠습니다.
def gradient(x, w, b, y):
dw = (loss(x, w + 0.0001, b, y )- loss(x, w, b, y)) / 0.0001 # w 기울기
db = (loss(x, w, b + 0.0001, y ) - loss(x, w, b, y)) / 0.0001 # b 기울기
return dw, db
cf) 하이퍼 파라미터 : 학습시키는 파라미터 값이 아닌 사람이 직접 사전에 지정하는 파라미터
learning rate를 하이퍼파라미터값으로 설정해 주겠습니다.
LERANING_RATE = 1
모델의 최적화
이제 모델 최적화에 대한 코드를 구현해 보도록 하겠습니다.
x = macbook['used_year'].values # x값 할당
y = macbook['price'].values # y값 할당
w = 3.1 # 랜덤으로 w초기값 설정
b = 2.3 # 랜덤으로 b초기값 설정
losses = [] # 손실함수의 값을 저장하는 list
LEARNING_RATE = 1 # 하이퍼 파라미터로 학습률 설정
for i in range(1, 2001):
dw , db = gradient(x, w, b, y) # 모델이 predcition을 예측하고 손실함수값을 계산한 후 바로 기울기값 계산
w -= LEARNING_RATE * dw # w의 값을 갱신
b -= LEARNING_RATE * db # b의 값을 갱신
L = loss(x, w, b, y) # 현재의 loss값
losses.append(L) # loss 값 기록
if i %100 == 0:
print('Iteration %d : Loss %0.4f' % (i, L))
# 시각화
plt.plot(losses)
plt.show()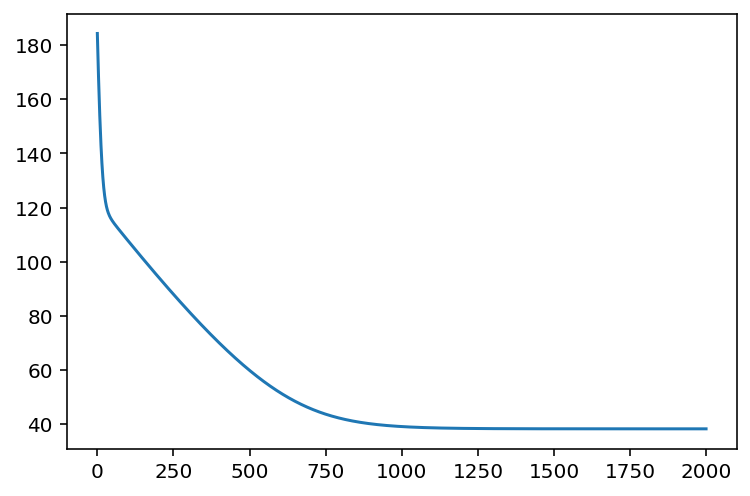
초기에 180이였던 값이 40이하로 잘 떨어졌습니다.
맥북 데이터와 학습이 완려된 모델이 잘 피팅이 되었는지 살펴보겠습니다.
# 예측한 모델에 일치하는 일차원함수 그리기
x = np.linspace(0, 5, 6)
y = model(x, w, b)
plt.plot(y, c = 'r')
# 맥북데이터 그리기
plt.scatter(macbook['used_year'], macbook['price'])
plt.show()
'TIL(Today I Learned)' 카테고리의 다른 글
| likelihood와 머신러닝 (0) | 2023.09.12 |
|---|---|
| scikit-learn을 이용해 분류문제 해결하기 (0) | 2023.09.05 |
| 시계열 데이터 분석, 예측하기 (1) | 2023.08.31 |
| 데이터 분석 (0) | 2023.08.30 |
| 머신러닝 모델설계하기 기초 | 내가 받을 팁 예측하기 (2) (0) | 2023.08.28 |



