설치 및 improt
pip install scikit-learnimport sklearn
print(sklearn._version_)skit - learn의 주요 메소드
- Transformer()
- from sklearn.model_selection import train_test_split
- fit()
- predict()
데이터 표현법
- skit - learn에서는 numpy의 Ndarray, pandas의 DataFrame, scipy의 Sparse Matrix로 데이터셋을 제공한다.
- skit - learn은 데이터를 보통 Feature matrix(특성 행렬)과 Target vector(타겟 벡터)로 나타냅니다.
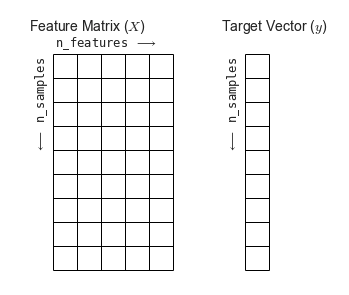
- Feature matrix
- 입력 데이터를 의미
- feature : 데이터에서 수치 값, 이산 값, 불리언 값으로 표현된느 개별 관측치를 의미, 열에 해당하는 값
- sample : 각 입력 데이터, 특성 행렬에서는 행에 해당
- n_samples : 행의 개수(표본의 개수)
- n_features : 열의 개수 (특성의 개수)
- x : 통상 특성 행렬은 변수명 x로 표시
- [n_samples, n_features]는 [행, 열]형태의 2차원 배열 구조를 사용함.
- Target vector
- 입력 데이터의 라벨(정답)을 의미
- Target : 라벨, 타겟값, 목표값이라고 하며, Feature matrix로 부터 예측하고자 하는 것을 의미
- n_smaples : 벡터의 길이(라벨의 개수)
- 타겟 벡터에서 n_features는 없음
- y : 통상 타켓 벡터는 변수명 y로 표기
- 타겟 벡터는 보통 1차원 벡터로 나타냄
Sklearn으로 데이터 살펴보기
from sklearn.datasets import load_wine # sklearn의 load_wine 데이터를 불러옴
data = load_wine()
data.keys() # sklearn의 번치데이터 type도 key로 접근 가능
# 출력 : dict_keys(['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names'])
data.data # feature matrix
data.targe # target vector
data.feature_names # 특성들의 이름
data.target_names # 분류하고자 하는 대상
data.DESCR # 데이터에 대한 설명을 출력
data.data.shape # data의 모양을 확인
data.data.ndim # data의 차원을 확인
improt pandas as pd
pd.DataFrame(data.data, columns = data.feature_names) # Data Frame으로 데이터 나타내기
Sklearn을 사용한 머신러닝
# target, feature data 변수 할당
X = data.data
y = data.target
# model불러오기
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier()
# model훈련시키기
model.fit(X,y)
# 예측하기
y_pred = model.predict(X)
# 성능 평가
from sklearn.metrics import accuracy_score
from sklearn.metrics import classification_report
# report를 출력
print(classification_report(y, y_pred))
# 출력
'''
precision recall f1-score support
0 1.00 1.00 1.00 59
1 1.00 1.00 1.00 71
2 1.00 1.00 1.00 48
accuracy 1.00 178
macro avg 1.00 1.00 1.00 178
weighted avg 1.00 1.00 1.00 178
'''
# 정확도를 출력
print(accuracy_score(y,y_pred)
# 출력 : accuracy = 1.0Estimator객체
: 데이터셋을 기반으로 머신러닝 모델의 파라미터를 추정하는 객체
- sklearn의 모든 머신러닝 모델은 Estimator라는 파이썬 클래스로 구현되어 있다.
- 모델의 훈련과 예측은 Estimator 객체의 fit(), predict()메서드를 사용한다.
- 비지도 학습은 target vector가 들어가지 않는다. model.fit(X)로 사용한다.
train data, target data 분리하기
데이터가 주어졌을 때 학습을 진행할 train data와 test를 진행할 test data를 나눠주어야한다. 이때 사용한느 함수가 sklearn의 train_test_split이다.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y , test_size = 0.2, random_state = 42)
이정도만 알고계시면 sklearn을 사용하여 간단한 모델을 구현할 수 있을겁니다.
오늘도 머신러닝에 한발짝-
'하루 30분 머신러닝, 딥러닝 기초다지기' 카테고리의 다른 글
| 하이퍼파라미터와 네트워크 깊이의 관계성 Learning Rate, Epoch (0) | 2024.12.02 |
|---|---|
| 머신러닝 알고리즘 (0) | 2023.09.07 |
| Regularization(정규화) Ridge vs Lasso (0) | 2023.09.06 |


