머신러닝 알고리즘이란
- 머신러닝 : 데이터로부터 자동으로 모델을 생성하는 방법
- 머신러닝 알고리즘 : 데이터 집합을 모델로 바꿔주는 알고리즘
대표적인 머신러닝 알고리즘 3가지
- 지도학습 (Supervised Learning)
- 비지도학습 (Unsupervised Learning)
- 강화학습 (Reinforcement Learning)머신러닝에서 알고리즘은 가장 크게 지도와 비지도, 강화학습으로 나눌수 있다. 지도 학습은 정답이 포함된 문제를 학습데이터로 제공한다. 이와 반대로 비지도 학습은 정답이 없는 데이터를 제공해서 알고리즘이 스스로 데이터를 살펴보고 유의미한 결과를 도출하게 한다. 머신러닝 알고리즘은 우리가 구현하고자하는 용도에 따라 선택할 수 있고, 또 합쳐서 사용될 수도 있다. 어떤 알고리즘을 선택할지는 데이터의 크기/품질/특성, 가용연산 시간, 작업의 긴급성, 데이터를 이용해 하고 싶은 것에 따라 달라진다. 그래서 최적의 성과를 내는 알고리즘을 찾기위해서 다양한 모델을 시도해보아야한다.
1. 지도 학습 (Supervised Learning)
: label이 지정된 데이터를 넘겨준다.
- 기존에 labele된 data를 training data로 넣어 모델을 학습시킨다.
- 알고리즘을 이용해 학습 데이터를 분석함하여 예측값과 실제값이 매핑되는 함수를 찾는다.
- 이렇게 추론된 함수는 학습용 데이터로의 일반화를 통해 학습하지 않은 새로운 data들의 결과를 예측한다.
- 지도학습은 학습 데이터의 패턴을 외우는 학습법에 불과하기 때문에 한번도 보지 않은 데이터를 잘 맞추는 것이 어렵다.
지도학습의 대표적인 알고리즘
- 분류(Classification) : 예측해야할 데이터가 범주형(categorical) 변수일때 분류 라고 함.
- 회귀((Regression) : 예측해야할 데이터가 연속적인 값 일때 회귀 라고 함.
- 예측(Forecasting) : 과거 및 현재 데이터를 기반으로 미래를 예측하는 과정.
2. 준지도 학습 (Semi-supervised Learning)
: 적은양의 labeled data와 대용량의 unlabeled data를 넘겨준다.
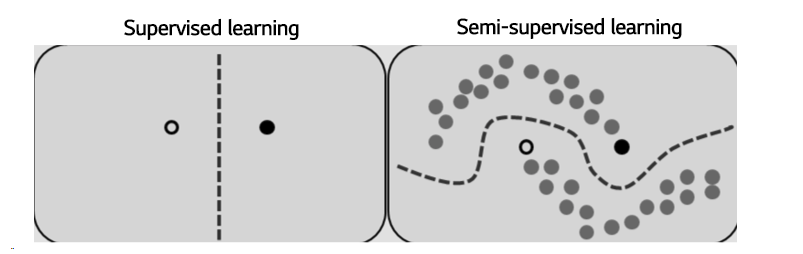
- 지도학습은 데이터 라벨링에 많은 비용과 시간이 소요될 수 있다.
- 이것을 보완하기 위해 라벨링된 자료가 한정적일 때 지도학습의 개선을 위해서 labeling이 되지 않은 자료를 사용한다.
- 이때 모델이 온전히 지도를 받지 않기 때문에 준지도를 받는다고 표현하다.
- 준지도 학습은 학습 정확성을 개선하기 위해 unlabeled 사례와 함께 소량의 labeled된 데이터를 사용해 성능 향상을 목표로한다.
3. 비지도(자율) 학습 (Unsupervised Learning)
: label이 지정되지 않은 데이터를 넘겨준다.

- machine은 unlabeled된 데이터만 제공 받는다
- 사람의 개입없이 데이터를 스스로 학습하여 그안의 pattern(패턴)이나 similarity(유사도)를 학습한다.
- 학습한 데이터를 바탕으로 새로운 data를 비슷한 집단으로 분류할 수 있다.
비지도 학습의 대표적인 알고리즘
- 클러스터링(clustering) : 특정기준에 따라 유사한 데이터끼리 군집화 현성
- 차원축소 (dimensionality reduction): 고려해야할 변수를 줄이는 작업, 변수와 대상간 진정한 관계를 도출하기 용이
4. 강화 학습 (Rainforcement Learing)
: 정적 dataset에 의존는 것이 아니라 역동적인 환경에서 동작하며 수집된 경험으로부터 학습한다.

- 강화학습 용어정리
- 에이전트 (Agent) : 학습 주체
- 환경 (Environment) : 에이전트에게 주어진 환경, 상황, 조건
- 상태 (State)
- 행동 (Action) : 환경으로부터 주어진 정보를 바탕으로 에이전트가 판단한 행동
- 보상 (Reward) : 행동에 대한 보상을 머신러닝 엔지니어가 설계
- 지도, 비지도 학습과는 다른 종류의 알고리즘이다
- 환경을 관찰해서 에이전트가 스스로 행동하게 한다.
- machine은 그 결과로 특정보상을 받아 이 보상을 최대화하도록 학습한다.
- machine은 최고의 보상을 산출하는 액션을 발견하기 위해 서로 다른 시나리오를 시도한다.
- 보상을 통해 상은 최대화, 벌은 최소화하는 방향으로 학습한다.
- 강화학습의 Trial-and error(시행착오)와 delayed reward(지연보상)는 다른 기법과 구별되는 특징이다.
- 강화학습의 이러한 점은 지도와 비지도학습에서 필요한 training전 데이터 수진, 전처리, 레이즐 지정에 대한 필요성을 해소한다.
강화학습의 대표적인 알고리즘
- Monte Carlo methods
- Q-Learning
- Policy Gradient methods
오늘을 4가지의 머신러닝 알로리즘의 큰틀을 알아봤습니다. 우리가 다룰 데이터에 따라 어떤 알고리즘을 사용하는 것이 좋을지 변하게 됩니다. 그렇기에 각각의 알고리즘의 case를 이해하는 것이 중요하고 우리가 해결할 문제가 어디에 해당하는지 파악하는 것이 굉장히 중요합니다. 그럼 오늘도 머신러닝에 한발짝 -
'하루 30분 머신러닝, 딥러닝 기초다지기' 카테고리의 다른 글
| 하이퍼파라미터와 네트워크 깊이의 관계성 Learning Rate, Epoch (0) | 2024.12.02 |
|---|---|
| Skit - learn으로 머신러닝 구현해 보기 (1) | 2023.09.07 |
| Regularization(정규화) Ridge vs Lasso (0) | 2023.09.06 |


