- 큐(Queue) : 먼저 들어오는 데이터가 먼전 나가는 선입선출(FIFO) 구조
- 우선순위 큐(Priority Queue) : 우선순위가 높은 데이터가 먼저 나가는 구조
- 힙(Heap) : 루트 노드에 최대값이나 최소값을 저장하고 있는 완전이진트리
📍 힙(heap)이란?
Heap은 완전이진트리 형태의 자료구조로 우선순위 큐를 위하여 만들어지 자료구조이다.
여러개의 값들 중에서 최댓값이나 최솟값을 빠르게 찾아내도록 만들어진 자료구조이다.
힙(heap)은 완전히 정렬된 구조가 아니라 "부분적으로 정렬된"(느슨하게 정렬된) 구조이다.
즉, 전체가 오름차순이나 내림차순으로 정렬되어 있는 것이 아니라, 부모 노드의 값이 자식 노드의 값보다 항상 크거나(최대힙) 작다(최소힙)는 조건만 만족하면 된다.
- 최대 힙(max heap) : 부모 노드의 키값이 자식 노드보다 큰 구조
- 최소 힙(min heap) : 부모 노드의 키 값이 자식 노드보다 작은 구조
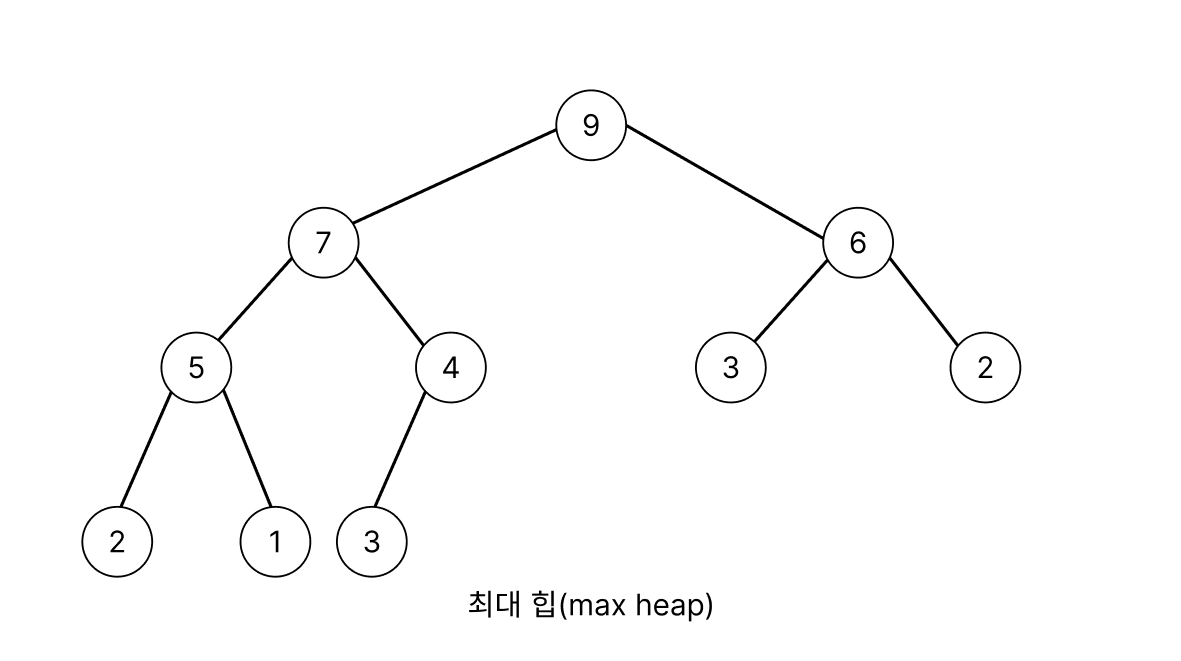
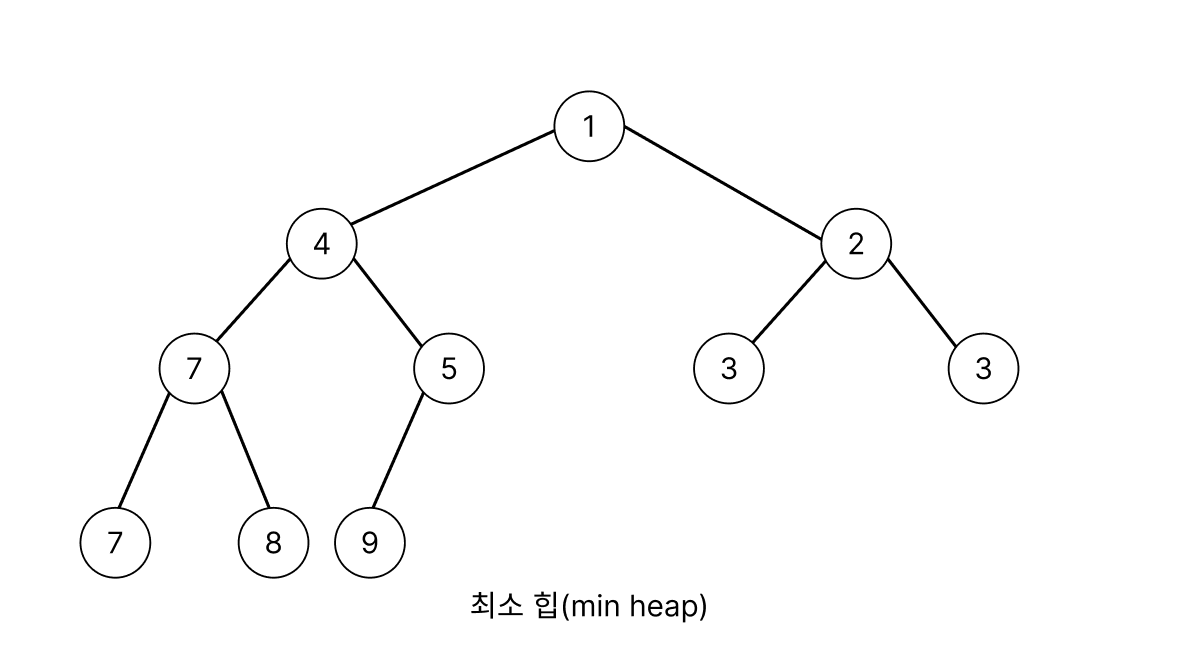
예를 들어,
최대 힙(max heap)의 경우 루트 노드가 전체 중 가장 큰 값을 가지고 각 부모 노드는 자신의 자식 노드보다 큰 값을 갖는다. 하지만 자식 노드들 간 크기 순서는 보장되지 않기 때문에 완벽하게 정렬된 상태가 아니다.
또한, 이진 탐색 트리에서는 중복된 값을 허용하지 않지만, 힙트리에서는 중복된 값을 허용한다.
이진 탐색 트리는 왼쪽 자식은 부모보다 작고 오른쪽 자식은 부모보다 크도록 정렬되기 때문에 보통은 중복값을 허용하지 않는다. 하지만 힙(heap)은 그냥 부모와 자식 간의 관계만 유지하면 되기 때문에 같은 값이 여러번 나올 수 있다.
완전이진트리는 마지막 레벨을 제외한 모든 레벨이 채워져 있고 마지막 레벨은 왼쪽부터 채워져있어야한다.
1️⃣ 힙(heap)의 구현
힙을 저장하는 표준적인 자료구조는 배열이다.
인덱스 계산을 단순화 하기 위해 배열의 첫번째 인덱스인 0은 사용하지 않는다. 이렇게 하면 각 노드의 위치(번호)가 트리내에서 고정되어, 새로운 노드가 추가되어도 기존 노드의 번호는 바뀌지 않는다.
✅ 인덱스 계산 방식

- 루트 노드 :
- 배열의 인덱스 1번부터 시작
- 루트노드는 항상 인덱스 1에 위치
- 부모와 자식 간의 관계 :
- 왼쪽 자식 : (부모의 인덱스) * 2 위치에 저장
- 오른쪽 자식 : (부모의 인덱스) * 2 + 1 위치에 저장
- 부모 노드 : (자식의 인덱스) / 2 -- 정수 나눗셈 위치에 저장
예를 들어, 루트 노드(인덱스 1)의 왼쪽 자식은 2 * 1 = 2 번, 오른쪽 자식은 2 * 1 + 1 =3번 인덱스에 위치하게 된다.
따라서 루트의 오른쪽 자식은 항상 인덱스 3번에 위치하게 되는 것이다.
이렇게 배열에 힙을 저장하면 트리 구조를 별도의 포인터 없이도 간단한 산술 연산만으로 부모와 자식간의 관계를 쉽게 찾을 수 있어 효율적인 구현이 가능하다.
2️⃣ 힙(heap) 삽입
힙에 새로운 요소가 들어오면, 일단 새로운 노드를 힙의 마지막 노드에 이어서 삽입한다.
이후, 새로운 노드를 부모 노드들과 교환해서 힙의 성질을 만족시킨다.
최대힙(max heap)에 새로운 요소 8을 삽입해보자.
1) 인덱스순으로 가장 마지막 위치에 이어서 새로운 요소 8을 삽입.

2) 부모 노드 4 < 삽입 노드 8 이므로 서로 교환.

3) 부모노드 7 < 삽입 노드 8 이므로 교환.

4) 부모노드 9 > 삽입노드 8 이므로 교환 안함.
3️⃣ 힙(heap) 삭제
최대힙에서의 삭제는 보통 최댓값을 제거하도록 되어 있다.
최댓값은 루트 노드이므로 루트 노드가 삭제된다.
최대 힙(max heap)에서 최댓값을 삭제해보자.
1) 최댓값인 루트 노드 9를 삭제.
2) 빈자리에 최대 힙의 마지막 노드를 가져옴.

3) 삽입 노드와 자식 노드를 비교하여 자식 노드 중 더 큰 값과 교환
자식노드 7 > 삽입노드 3 이므로 서로 교환

4) 삽입 노드와 자식노드를 비교.
자식노드 5 > 삽입노드 3 이므로 서로 교환

5) 삽입 노드와 자식노드를 비교.
자식노드 2 < 삽입노드 3 이므로 교환하지 않음
4️⃣ 힙(heap) C++로 구현하기
삽입
// heap 삽입
void push(int data){
// heap에 값 추가
heap_count++;
heap[heap_count] = data;
// 정렬
int child = heap_count;
int parent = child / 2;
// 자식노드가 부모노드 보다 값이 크면 교환
while( child > 1 && heap[child] > heap[parent]){
swap(&heap[parent], &heap[child]);
child = parent ;
parent = child / 2;
}
}
삭제
// heap 삭제
int pop(){
int result = heap[heap_count];
// 루트 노드의 값과 heap의 마지막 값 교환
swap(&heap[1], &heap[heap_count]);
// heap의 마지막 노드가 최댓값이기 때문에 heap_count를 -1하여 삭제
heap_count--;
// 정렬
int parent = 1 ;
int child = parent * 2;
if(child + 1 <= heap_count ){ // 자식 노드 중 더 큰값 찾기
child = (heap[child] > heap[child + 1]) ? child : child+1 ;
}
while(child <= heap_count && heap[child] > heap[parent]){
swap(&heap[child], &heap[parent]);
parent = child;
child = parent * 2;
if(child + 1 <= heap_count){
child = (heap[child] > heap[child + 1]) ? child : child + 1;
}
}
return result;
}
전체 코드
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#define HEAP_SIZE 256
#define ARRAY_SIZE 10
// heap의 인덱스 변수
int heap_count = 0;
int heap[HEAP_SIZE];
void swap(int *a, int *b){
int tmp = *a;
*a = *b ;
*a = tmp;
}
// heap 삽입
void push(int data){
// heap에 값 추가
heap_count++;
heap[heap_count] = data;
// 정렬
int child = heap_count;
int parent = child / 2;
// 자식노드가 부모노드 보다 값이 크면 교환
while( child > 1 && heap[child] > heap[parent]){
swap(&heap[parent], &heap[child]);
child = parent ;
parent = child / 2;
}
}
// heap 삭제
int pop(){
int result = heap[1];
// 루트 노드의 값과 heap의 마지막 값 교환
swap(&heap[1], &heap[heap_count]);
// heap의 마지막 노드가 최댓값이기 때문에 heap_count를 -1하여 삭제
heap_count--;
// 정렬
int parent = 1 ;
int child = parent * 2;
if(child + 1 <= heap_count ){ // 자식 노드 중 더 큰값 찾기
child = (heap[child] > heap[child + 1]) ? child : child+1 ;
}
while(child <= heap_count && heap[child] > heap[parent]){
swap(&heap[child], &heap[parent]);
parent = child;
child = parent * 2;
if(child + 1 <= heap_count){
child = (heap[child] > heap[child + 1]) ? child : child + 1;
}
}
return result;
}
int main(){
int arr[ARRAY_SIZE];
srand(time(NULL));
// 랜덤 값으로 배열생성
for(int i=0; i < ARRAY_SIZE; i++){
arr[i] = rand() % 50 + 1;
}
// heap초기화
for(int i=0; i < ARRAY_SIZE; i++){
push(arr[i]);
}
// heap에서 꺼내면서 값 확인
for(int i = 0; i<ARRAY_SIZE; i++){
printf("%d", pop());
}
printf("\n");
return 0;
}코드 참고 : https://twpower.github.io/137-heap-implementation-in-cpp
참고
https://gmlwjd9405.github.io/2018/05/10/data-structure-heap.html
[자료구조] 힙(heap)이란 - Heee's Development Blog
Step by step goes a long way.
gmlwjd9405.github.io
https://be-senior-developer.tistory.com/25
[최소 힙] c++ 구현 및 설명
이미지 출처:https://namu.wiki/w/%ED%9E%99%20%ED%8A%B8%EB%A6%AC 힙의 정의 우선 순위 큐를 이해하기 위해서는 힙이라는 것을 알아야 한다. 완전 이진트리의 일종으로 최댓값 및 최솟값을 찾아내는 연산을 빠
be-senior-developer.tistory.com
https://velog.io/@yun8565/%EC%9A%B0%EC%84%A0%EC%88%9C%EC%9C%84-%ED%81%90-Priority-Queue
우선순위 큐 (Priority Queue)
큐는 먼저 들어오는 데이터가 먼저 나가는 선입선출 (FIFO) 형식의 자료구조지만 우선순위 큐는 들어오는 순서에 상관 없이 우선순위가 높은 데이터가 먼저 나가는 자료구조이다.우선순위 큐는
velog.io
'TIL(Today I Learned)' 카테고리의 다른 글
| [자료구조] 우선순위 큐(Priority Queue)C++ 구현 (0) | 2025.03.25 |
|---|---|
| YOLO - You Only Look Once Real-Time Object Detection 논문 리뷰 (0) | 2025.03.06 |
| NOTION 노션 slice()함수 에러,ERROR : text 유형의 인수가 slice() 함수를 만족하지 않습니다. (0) | 2025.02.21 |
| [python] 파이썬 슬라이싱 기본 개념 (0) | 2024.09.26 |
| 모델 저장과 Callback (0) | 2023.10.13 |


