YOLO는 ML/CV의 많은 발전을 주도하고 Object Dtection의 새로운 획을 그은 모델이라고 할 수 있다. 2015년 발표된 이후 지금까지 꾸준한 업데이트를 통해 많은 분야에서 널리 사용되고 있다.
많은 사람들의 관심을 받은 만큼 여러 논란과 발전이 있었던 YOLO 모델에 대해 살펴보고자 한다.
📍 YOLO란 ?

YOLO는 Real time Object Detection을 가능하게 해준 대표적인 모델이다.
YOLO의 저자는 Joseph Redmon로 ML/CV의 많은 발전을 기여했다.
( YOLOv3를 마지막으로 지금은 업계를 떠남ㅠ, 자신이 개발한 기술이 도덕적으로 문제가 될 수 있는 분야에서 사용될 수 있다는 우려를 표명하며, AI 연구의 영향력에 대해 회의를 느끼고 은퇴를 선언했다. )

2015-16년 당시에 R-CNN 계열의 Two-stage방식이 주류를 이루고 있던 당시 네트워크를 단일화 하여 빠른속도로 Object Detection을 할 수 있게 해준 모델이다. UC Berkeley의 딥러닝 프레임워크인 Caffe를 사용하지 않고 독자적으로 개발한 Darknet 프레임 워크를 사용해 YOLO를 개발하였다.
YOLOv1은 Pascal VOC 2007 기준 정확도는 mAP 63.4, 속도는 45FPS를 보인다.
당시 SOTA모델 이였던 Faster R-CNN이 mAP 73.2 & 7 FPS 혹은 mAP 62.1 & 18FPS를 기록한 것과 비교하면 속도와 정확도의 Trade-off를 감안할 때 매우 뛰어난 성능이였다.
YOLOv1은 크기가 작은 객체, 가까이에 있는 다수의 객체( like, 새때)에 대한 한계가 있었지만 그럼에도 뛰어난 모델이다.
YOLOv1에 관한 더 자세한 설명은 아래의 블로그에 상세히 작성해 두었다.
https://codinghago.tistory.com/94
YOLO - You Only Look Once Real-Time Object Detection 논문 리뷰
📍 YOLO(You Only Look Once)란? YOLO는 Real Time Object Detection으로 2015년 조셉 레드몬에 의해 등장했다. Object Detetion은 two-stage와 one-stgae로 분류할 수 있다. YOLO는 one-stage로 YOLO이전의 Classifier를 base로 하
codinghago.tistory.com
YOLOv2 (2017년) - YOLO9000
논문 - "YOLO9000: Better, Faster, Stronger"

✅ Architecture
- 기존의 Darknet을 개선한 Darknet 19사용.
- 기존 network의 마지막 Fully Connected layer를 제거하고 1x1 Convolution Layer로 대체했다.
- Anchor Boxes도입 : Faster R-cnn처럼 미리 정의된 Anchor Box사용하여 예측 성능 개선.
- v1에서는 Grid 당 2개의 B - Box 좌표를 예측하는 방식이었다면 YOLOv2에서는 Grid당 5개의 Anchor Box를 찾는다.
- Global Average Pooling을 사용해 파라미터를 줄여 속도 향상
💡 Anchor Box란?
미리 정의된 여러 크기의 박스를 사용하여 객체의 위치를 예측하는 방법.
YOLOv1에서는 하나의 그리드에서 최대 2개의 바운딩 박스만 예측할 수 있었지만 YOLOv2에서는 Faster R-CNN에서 사용되었던 Anchor Box개념을 적용하여 미리 정의된 여러개의 Anchor Box(=기본 바운딩 박스 형태)를 기반으로 크기를 보정하여 예측하는 방식을 사용했다. 이를 통해 다양한 크기의 객체를 탐지할 수 있도록 성능이 개선되었다.
✅ 주요 개선점
- High - resolution classifier 적용하여 성능 향상
- 기존 모델이 224x224 size로 Pre-train하고 , 448x448 size를 input으로 사용하여 불안정한 학습이 이루어 진걸과 달리 448x448 size로 Pre-train하는 것으로 변경하여 mAP가 약 4% 향상되었다.
- Fine-grained features적용
- 중간 feature맵과 최종 feature맵을 합쳐 이용한다. 즉, 앞 Convolution Layer의 High Resolution Feature Map을 뒷 단의 Convolution Layer의 Low Resolution Feature Map에 추가한다.
- 중간 feature맵은 지역적 특성을 잘 반영하기 때문이다. 그래서 High Resolution Feature는 작은 객체에 대한 정보를 함축하고 있기 때문에 작은 객체 검출에 강할 수 있도록 했다.
✅ 알쓸신잡
9000종류 이상의 객체를 분류할 수 있다는 의미로 YOLO9000이라고 명명했으나 YOLOv2라고 지칭된다.
Joseph은 해당 논문으로 CVPR 2017 Best Paper Honorable Mention Award를 수상했다.
YOLOv3 (2018년)
논문 - "YOLOv3: An Incremental Improvement"

✅ Architecture
- Darknet - 53백본을 사용하여 ResNet스타일의 Residual Block을 도입
- 이전 Darknet-19에 ResNet에서 제안된 skip connection 개념을 적용하고 Pooling layer를 삭제
- SSD 모델의 Multi-Scale Feature Layer와 Retinanet의 FPN(Feature Pyramid Network)와 유사한 기법을 적용한다.
- Feature Pyramid Network(FPN) 적용하여 작은 객체 검출 성능 향상
- 다중 스케일 예측 : 3개의 다른 크기의 Feature Map에서 객체 검출
- 다중 스케일 예측으로 작은 객체 탐지 성능 개선
- Binary Cross-Entropy Loss 도입하여 Softmax대신 독립적인 Binary Classifier사용
✅ 주요 개선점
- 정확도 향상(mAP 증가) 및 속도 유지
- Multilabel Classification
- 만약 사람이면서 동시에 여성이라고 할 때, 한 물체에 대한 multi classlabel을 가질 수 있다. 그러나 softmax는 한 박스 안에서 여러 객체가 존재할 경우 적절하게 포착할 수 없었다.
- 하지만 v3에서는 이것이 가능하도록 마지막에 Loss Function을 softmax가 아닌 모든 class에 대해 sigmoid를 취해 각 class별로 binary classification 을 하도록 바꾸었다.
✅ 알쓸신잡
YOLOv3는 원 개발자였던 Joseph이 개발한 마지막 YOLO이다. Joseph은 YOLOv3 발표이후 윤리적인 이유로 Computer Vision 분야 연구를 그만둘 것임을 공표했다. 자신이 개발한 기술이 '대기업의 사생활 침해'나 '군사적 목적의 사용'에 대한 우려를 가지고 있으면서도 'Google'과 '미 해군연구소'의 펀딩을 받으며 연구하고 있는 자신의 위치에 대해 자조적인 농담과 함께 논문에 언급했다. 쨌든 YOLOv3은 그의 마지막 YOLO가 되었다.
YOLOv4 (2020년)
논문 - "YOLOv4: Optimal Speed and Accuracy of Object Detection"
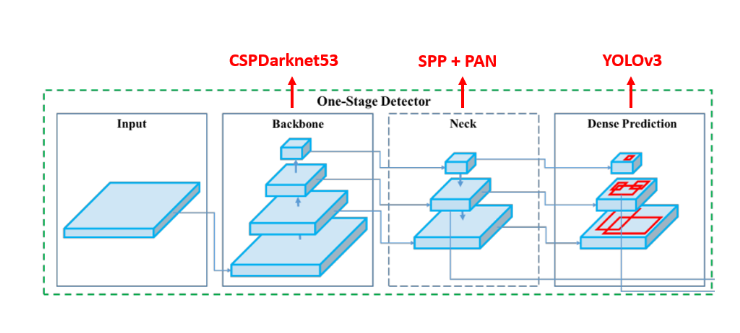
✅ Architecture
정확도를 높이고 속도문제는 Architecture변경을 통해 해결했다.
- CSPDarknet53백본 사용
- Cross Stage Partial Networks 적용하여 연산량 감소
- Spatial Pyramid Pooling(SPP)추가 :
- 다양한 크기의 Pooling 적용하여 컨텍스트 정보 활용
- Path Aggregation Network (PANet)적용 :
- Feature Pyramid Networks개선하여 정보 흐름 강화
✅ 주요 개선점
- YOLOv4는 기존 YOLO시리즈의 작은 객체 검출 문제를 해결하고자 한것이 특지앋.
- 작은 Object들을 잘 검출하기 위해 Input 해상도를 크게 사용했다. 기존에는 224, 256 등의 해상도를 이용하여 학습을 시켰다면, YOLOv4에서는 512를 사용했다.
- Recepive field를 물리적으로 키워 주기 위해 layer수를 늘렸으며, 하나의 image에서 다양한 종류, 다양한 크기의 object들을 동시에 검출하려면 높은 표현력이 필요하기 때문에 parameter수를 키워주었다.
- Mish 활성화 함수 도입하여 학습 안정화
- Self-Adversarial Training(SAT)추가하여 모델이 자체적인 Adversarial Attack방어가능
- 성능 (mAP: 60.0%), 정확도 향상, 속도 감소, 더 정확한 객체 검출
✅ 알쓸신잡
새로운 개발자 Alexey의 YOLO이다. Joseph의 은퇴 이후 YOLO연구가 끝날것이라고 예상했지만 새로운 개발자인 Alexey에 의해 v4가 발표되었다. 새로운 인물이 YOLO의 유명세에 편승한다는 목소리도 나왔지만 Joseph의 아래와 같은 트윗으로 일단락 되었다.

Alexey의 YOLOv4는 추론시간 증가 없이 정확도를 향상시키는 Bag of Freebies(BoF)와, 추론시간을 약간 증가시키면서 정확도를 크게 향상시키는 Bag of Specials(BoS)라는 두 기법을 도입, 정확도-속도 간 균형을 이루며 YOLOv3 모델 대비 정확도(55.3→62.8)와 속도(34→54)모두 향상된 결과를 보였다.
YOLOv5
✅ Architecture
- Darknet기반이 아닌 Pytorch를 사용했다.
- Focus Layer추가하여 CNN특징 추출 최적화
- Mosaic Augmentation 적용하여 여러 이미지를 합쳐 데이터 증강 효과 제공
✅ 주요 개선점
- yolo v5 s, yolo v5 m, yolo v5 l, yolo v5 x로 버전을 나눈다.
- s가 가장 빠르지만 정확도는 x가 가장 좋다.

✅ 알쓸신잡
v5는 YOLO시리즈 중 가장 논란이 되었던 버전이다. paper없이 발표하였기 때문이다. YOLOv4대비 성능이 개선되었다고 주장하였지만 논문이 발표되지 않았기 떄문에 모델 구조와 성능은 검증되지 않았다. 또한 원작자로 부터 허락을 받았던 Alexey가 개발한 모델도 아니였고 YOLO의 아키텍처와 네이밍을 사용하면서고 YOLOv1~ v4와 같이 all-permissive라이선스를 따르지 않고 상업화 목적으로 공개되었다는 것 등의 여러 이유가 있었다.
하지만 C언어 기반의 Darknet이 아닌 PyTorch기반으로 구현되어 딥러닝 연구자들이 쉽게 접근할 수 있었고 n/s/m/l/x 등 여러 사이즈의 pre-trained 모델을 제공해 목적에 맞게 속도-정확도 균형을 선택할 수 있는 등 다양한 업데이로 많은 인기를 얻었다. 이 밖에도 이미지/동영상 파일 혹은 폴더, 웹캠 스트리밍 등 다양한 입력 포맷과 iOS/안드로이드 등 모바일을 포함한 많은 OS들을 지원하고, Mosaic 방식의 데이터 증강 기법을 도입해 적은 데이터로도 준수한 성능을 낼 수 있는 등, 실사용 측면에서 상당한 개선을 이뤘다.
YOLOv8 (2023년)
이후YOLO 시리즈는 모두 저자가 다르며 최근 제일 많이 사용되는 YOLOv8을 기준으로 살펴볼 때 YOLOv8은 Ultralytics에서 개발되었다. YOLO모델을 위한 완전히 새로운 리포지토리를 출시하여 개체 감지, 인스턴스 세분화 및 이미지 분류 모델을 train하기 위한 통합 프레임 워크로 구축되었다.
✅ Architecture
- CBAM (Convolutional Block Attention Module) 도입하여 채널 및 공간 주의 메커니즘 적용
- Decoupled Head 사용: Classification과 Regression을 분리하여 성능 최적화
✅ 주요 개선점
- 이미지 분할(Segmentation) 및 키포인트(Keypoint) 검출 기능 추가
- 기존 YOLO 모델 대비 경량화된 구조로 속도 향상
✅ 알쓸신잡
YOLOv8은 오픈소스 라이선스 중 비교적 폐쇄적인 AGPL 3.0 라이선스를 채택되었다. Ultralytics 프레임워크 기반으로 개발된 v9, v10 모델 구현체들도 같은 라이선스를 따르게 되어, v8 이후 모든 YOLO 모델들이 초기 YOLO와 달리 연구 외 상업적 이용에 제약(소스코드 공개 의무)이 생겼다.
정리하다 보니 YOLO가 인공지능과 CV산업에 미치는 영향이 커서 그런지 재미있는 이야기들도 찾아 볼 수 있길래 함께 정리하게 되었다. 개인적으로 YOLOv8을 사용했을 때 다양한 Pretrained된 모델을 선택할 수 있다는 점이 굉장한 장점으로 다가왔다. Ultralytics에 공식문서도 잘 정리되어 있어서 누구나 쉽게 인공지능을 사용할 수 있는 때가 온것 같다.
Reference
https://velog.io/@qtly_u/n4ptcz54
[YOLO] YOLO 버전 - Yolo v1부터 Yolo v8까지 (23.03.기준)
이번 글에서는 YOLO 시리즈별 구조 및 특징에 대해 정리해보겠습니다. 23년 3월 기준 YOLO는 버전 8까지 나와있습니다. < YOLO 버전별 출시 시점 > - YOLOv1 : 2016년에 발표된 최초 버전으로, 실시간 객체
velog.io
https://devocean.sk.com/blog/techBoardDetail.do?ID=166976&boardType=techBlog
From One to Ten: YOLO 시리즈 변천사
devocean.sk.com
https://velog.io/@juneten/YOLO-v1v9#22-training
YOLO모델 및 버전별 차이점 분석
2016년에 발표된 최초 버전물체가 작을수록 정확도가 감소한다.여러 물체가 겹쳐있을 경우 제대로된 예측이 어렵다.Bounding Box 형태가 data를 통해 학습되므로 새로운 형태의 Bounding Box의 경우 정확
velog.io