https://codinghago.tistory.com/73
Union-Find (Disjoint-Set) Data Structure -1
1. Union-Find 란?Union-Find는 disjoint(겹치지 않는) 집합들의 모음을 관리하는 자료 구조이다. 각 요소는 하나의 집합에 속하며, 초기에는 각 요소가 독립적인 단일 집합으로 시작한다.전체 원소는 n개
codinghago.tistory.com
1. Union-Find의 기본 구현의 단점
Union 연산을 반복할수록 트리가 높아질 수 있고 트리가 높아지면 Find 연산의 시간 복잡도가 커져 비효율적이 된다.
예를 들어 연속된 Union 연산으로 트리가 길게 늘어날 수 있다.
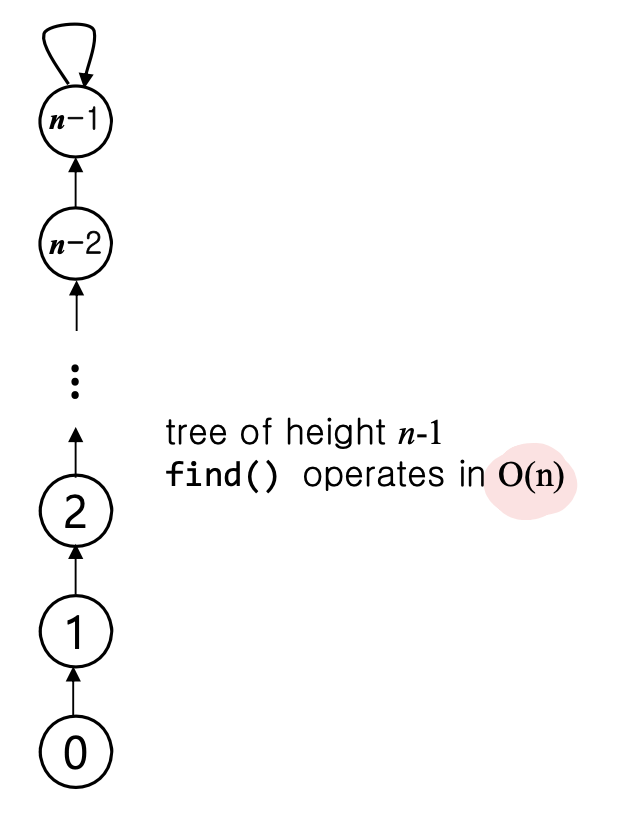
따라서, 트리가 길어지지 않도록 트리의 높이를 줄이는 방법을 도입해야 하고 이를 통해 Find 연산의 시간 복잡도를 줄이고, Union-Find 자료 구조의 효율성을 개선해야한다.
2. Improvement 1 (Weighting)
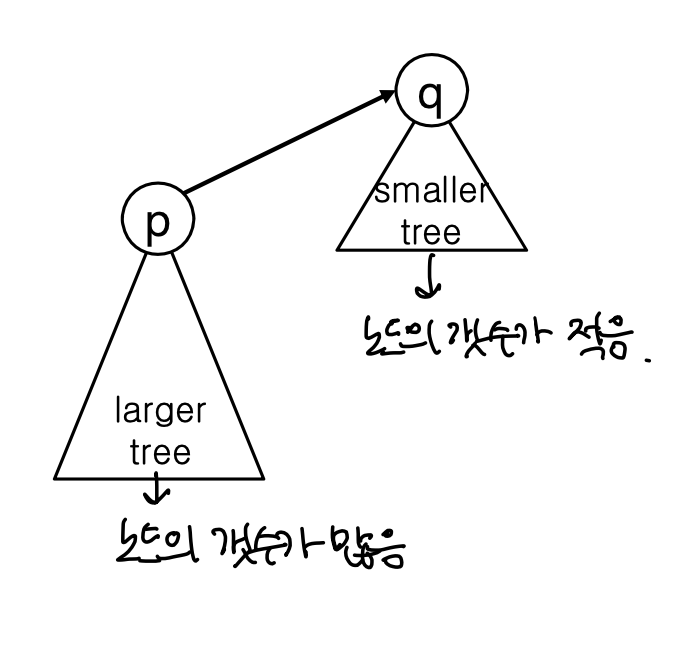
Weighting(가중치)개념을 사용해 두 집합을 병합할 때, 작은 트리를 큰 트리에 연결하여 트리가 높아지는 것을 방지할 수 있다.
이 방법은 Union-Find에서 Find와 Union 연산의 평균 시간 복잡도를 개선하는 핵심 기법으로 가중치를 사용해 트리의 크기(요소 개수)를 추적하고, 이를 기준으로 병합 방향을 결정한다.
구현 방법:
- 추가 배열 sz[]를 사용하여 각 트리의 크기를 저장.
- sz[i]: 트리 i의 요소 개수.
- Union 연산 시:
- 두 트리의 루트를 비교.
- 크기가 작은 트리를 크기가 큰 트리의 루트에 연결.
- 병합 후, 큰 트리의 크기를 업데이트.
예시:
- p = 5, q = 9:
- 5의 루트: 1 (sz[1] = 3)
- 9의 루트: 4 (sz[4] = 2)
- sz[1] > sz[4]: 크기가 큰 트리 1에 4를 연결.
- 결과:
- pt[4] = 1
- sz[1] = 5 (새 트리의 크기).
이렇게 하면 트리의 높이가 증가하는 속도를 줄일 수 있고 최악의 경우, 트리의 깊이는 O(log n) 수준으로 유지할 수 있다.
def union(pt, sz, p, q):
rootP = find(pt, p) # p의 루트를 찾음
rootQ = find(pt, q) # q의 루트를 찾음
if rootP != rootQ: # 루트가 다르면 병합
if sz[rootP] < sz[rootQ]: # rootP의 트리가 더 작으면
pt[rootP] = rootQ # rootP를 rootQ의 자식으로 설정
sz[rootQ] += sz[rootP] # rootQ 트리의 크기 갱신
else: # rootQ의 트리가 더 작거나 같으면
pt[rootQ] = rootP # rootQ를 rootP의 자식으로 설정
sz[rootP] += sz[rootQ] # rootP 트리의 크기 갱신
'하루 30분 알고리즘 기초다지기' 카테고리의 다른 글
| 소수찾기 알고리즘 C++, 에라토스테네스의 체 (0) | 2025.03.27 |
|---|---|
| 다익스트라(Dijkstra) 알고리즘 최단경로 알고리즘 (0) | 2025.03.24 |
| Union-Find (Disjoint-Set) Data Structure -1 (2) | 2024.12.03 |
| 2차 동적계획법 이항계수 (binomial coefficient) 계산문제, 동전교환 문제 (1) | 2024.11.11 |
| 동적계획법 Dynamic Programming 동전 교환 문제 알고리즘 (0) | 2024.11.05 |


